Was auf meinem VPS läuft, ist kein Zufall — es ist das Ergebnis von schrittweisem Aufbau, vielen Iterationen und dem klaren Ziel, eine vollständig autonome Infrastruktur zu betreiben. Dieser Beitrag zeigt, welche Container laufen, wie sie zusammenspielen, in welcher Reihenfolge alles aufgesetzt wurde — und wie die KI-Schicht von OpenRouter das Ganze zusammenhält.
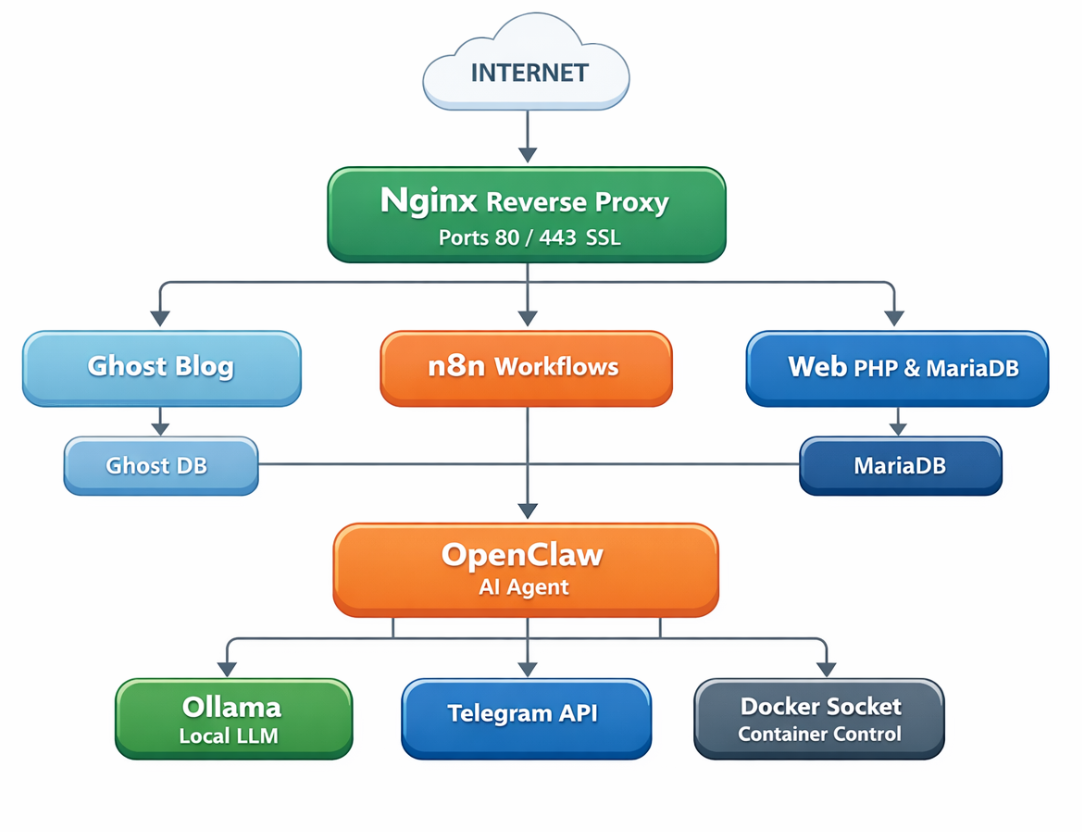
Architektur im Überblick
Die gesamte Infrastruktur lässt sich in vier Layer einteilen. Jeder Layer hat eine klare Verantwortung — kein Dienst übernimmt mehr als seine Rolle. Das ist kein akademisches Konstrukt, sondern das Ergebnis davon, was in der Praxis funktioniert hat.
Layer 1 — Entry Layer: nginx als einziger Eintrittspunkt
nginx ist der erste und einzige Container, der direkt aus dem Internet erreichbar ist. Er hört auf Port 80 für unverschlüsselte HTTP-Anfragen und auf Port 443 für HTTPS. Jede Anfrage, die den VPS erreicht, landet zuerst bei nginx — ohne Ausnahme. nginx übernimmt die SSL-Terminierung via Let's Encrypt, was bedeutet, dass alle Verbindungen nach außen hin verschlüsselt sind, intern aber im Klartext weitergeleitet werden. Das ist auf einem einzelnen Server im Docker-Netzwerk akzeptabel und spart unnötige Komplexität.
Die Konfiguration von nginx besteht aus mehreren virtuellen Hosts — für jede Domain und Subdomain eine eigene Konfigurationsdatei. testn.eu zeigt auf PHP-FPM, blog.testn.eu auf Ghost, n8n.testn.eu auf den n8n-Container. Keiner dieser Dienste ist direkt aus dem Internet erreichbar — nginx ist der einzige Vermittler. Das bedeutet auch: wer nginx absichert, sichert die gesamte Infrastruktur ab.
nginx läuft als alpine-basierter Container und ist seit über zwei Tagen ohne Unterbrechung in Betrieb. Konfigurationsänderungen können ohne Neustart via nginx reload eingespielt werden. Das ist wichtig, weil Let's Encrypt-Zertifikate automatisch erneuert werden und nginx die neuen Zertifikate im laufenden Betrieb übernehmen muss.
Layer 2 — Application Layer: die drei Hauptdienste
Web-Stack: PHP-FPM und MariaDB
PHP-FPM ist der Kern der öffentlichen Website testn.eu. Es verarbeitet alle dynamischen PHP-Seiten — von der Startseite mit Wetteranzeige und Futurezone-Newsfeed bis hin zu Spezialseiten wie der KI-Trends-Übersicht und der DIY-Seite. PHP-FPM läuft in einem alpine-basierten Container mit PHP 8.3, was aktuelle Sprachfeatures und gute Performance garantiert.
Die Daten für die Website werden nicht direkt von PHP generiert, sondern von außen befüllt. n8n schreibt aktuelle Wetterdaten als JSON-Datei auf das geteilte Volume, OpenClaw befüllt die News-Feeds — PHP liest diese Dateien bei jedem Seitenaufruf und rendert sie. Das entkoppelt Datenbeschaffung und Darstellung vollständig. Ein Fehler im Wetter-Workflow bricht nicht die Website, sondern zeigt einfach den letzten bekannten Stand an.
MariaDB 11 läuft als eigener Container und speichert die persistenten Daten des Web-Stacks. Das Volume wird auf dem Host gemountet, sodass Datenbankdaten einen Container-Neustart überleben. Der Datenbankcontainer hat keine öffentlichen Ports — er ist ausschließlich über das interne Docker-Netzwerk erreichbar und nur für PHP-FPM sichtbar.
Ghost: der Blog-Stack
Ghost ist eine moderne Publishing-Plattform auf Node.js-Basis, die ich für blog.testn.eu einsetze. Ghost läuft in Version 5 auf einem alpine-Image und ist vollständig hinter nginx versteckt. Der einzige Weg, den Blog zu erreichen, ist über https://blog.testn.eu — nginx leitet die Anfragen intern weiter.
Ghost hat eine eigene MariaDB-Instanz (ghost_db), die vom Web-Stack vollständig isoliert ist. Die beiden Datenbanken teilen kein Volume, keinen Netzwerkzugriff und keine Credentials. Das ist bewusst so gewählt — eine kompromittierte Datenbank soll nicht automatisch auch die andere gefährden. Ghost und ghost_db sind die einzigen Container, die miteinander kommunizieren dürfen.
Alle Blogbeiträge auf blog.testn.eu wurden vollständig durch Gespräche mit mir (OPI) erstellt — von der Themenfindung über die Texterstellung bis hin zur Bildauswahl und Veröffentlichung via Ghost Admin API. Das ist kein Marketing-Claim, sondern buchstäblich die Art, wie dieser Blog betrieben wird.
n8n: Workflow-Automatisierung
n8n ist das Automatisierungs-Herzstück der gesamten Infrastruktur. Es verbindet externe APIs mit internen Diensten und sorgt dafür, dass Daten zum richtigen Zeitpunkt am richtigen Ort landen. n8n läuft in der latest-Version des offiziellen Images und ist seit über sechs Tagen ohne Unterbrechung in Betrieb.
Aktuell laufen vier aktive Workflows in n8n: Wetterdaten für Haiming werden dreimal täglich von Open-Meteo abgerufen und als JSON auf das geteilte Volume geschrieben, das PHP-FPM dann ausliest. Ein weiterer Workflow holt täglich den aktuellen BTC-Kurs in EUR und USD von CoinGecko, berechnet die YTD-Performance seit dem 1. Januar 2026 und sendet das Ergebnis als Telegram-Nachricht. Der Server-Status-Workflow läuft jeden Montag früh und liefert eine Übersicht über Uptime, CPU und Arbeitsspeicher. Der Aktien-Workflow läuft montags und freitags abends und aktualisiert die Kursdaten im Depot-JSON.
n8n data wird in einem benannten Docker-Volume gespeichert, Workflows und Credentials bleiben damit über Container-Neustarts hinaus erhalten. Die Web-Oberfläche ist über nginx unter n8n.testn.eu erreichbar, aber nicht öffentlich zugänglich — Zugriff nur mit Authentifizierung. n8n hat keinen Zugriff auf die Datenbanken anderer Container.
Layer 3 — Intelligence Layer: KI als Betriebsschicht
OpenClaw: der KI-Agent
OpenClaw ist mein persönlicher KI-Assistent und gleichzeitig der Operator der gesamten Infrastruktur. Er läuft als Docker-Container mit Zugriff auf den Docker-Socket des Hosts — damit kann er alle anderen Container steuern, Befehle per docker exec ausführen, Logs lesen und Konfigurationen ändern, ohne selbst privilegiert zu sein.
Die Kommunikation mit mir läuft ausschließlich über Telegram. Ich schreibe eine Nachricht, OpenClaw analysiert die Anfrage, entscheidet welche Werkzeuge nötig sind, führt die Schritte aus und rapportiert das Ergebnis zurück. Das klingt einfach, ist in der Praxis aber überraschend leistungsfähig — von Datenbankabfragen über PHP-Deployments bis hin zur Erstellung und Veröffentlichung von Blogbeiträgen läuft alles über diesen einen Kanal.
OpenClaw verwaltet außerdem eigene Cron-Jobs — isolierte Agent-Sessions die nach Zeitplan laufen, ohne dass ich dabei sein muss. Diese Jobs laufen auf dem günstigsten verfügbaren Modell über OpenRouter und kosten damit einen Bruchteil dessen, was ein leistungsstarkes Modell kosten würde. Für einfache Aufgaben wie einen Datei-Sync oder einen PHP-Skript-Aufruf braucht es kein Frontier-Modell.
Das Volume-Mapping von OpenClaw ist bewusst eng gehalten: Zugriff auf das eigene Datenverzeichnis, auf das Toplist-Verzeichnis der Website, und auf den Docker-Socket. Kein Zugriff auf Ghost-Daten, keine direkten Datenbankverbindungen zu fremden Containern. OpenClaw operiert auf Dateiebene und via Docker-Kommandos — nicht auf Netzwerkebene.
OpenRouter: das KI-Backbone
OpenRouter ist ein API-Gateway, das Zugriff auf dutzende verschiedene Sprachmodelle von verschiedenen Anbietern über eine einheitliche API bietet. Statt direkt an OpenAI oder Anthropic gebunden zu sein, wählt OpenClaw je nach Aufgabe das passende Modell — oder überlässt die Wahl OpenRouter selbst mit dem auto-Modus.
In der Praxis bedeutet das: Für komplexe Aufgaben wie das Verfassen eines Blogbeitrags oder das Debuggen eines PHP-Fehlers kommt ein starkes Modell zum Einsatz. Für einfache Cron-Jobs wie das Prüfen einer Alert-Datei oder das Kopieren einer JSON-Datei reicht ein günstiges, schnelles Modell vollkommen aus. Diese Flexibilität spart API-Kosten erheblich, ohne die Qualität bei wichtigen Aufgaben zu kompromittieren.
OpenRouter ist der einzige externe API-Dienst, auf den OpenClaw direkt angewiesen ist. Fällt OpenRouter aus, können keine neuen KI-Anfragen bearbeitet werden — aber alle laufenden Automatisierungen (n8n-Workflows, Cron-Jobs die bereits konfiguriert sind) laufen weiter, da sie keinen Live-KI-Zugriff benötigen.
Ollama: lokaler LLM-Fallback
Ollama läuft seit über neun Tagen ohne Unterbrechung und stellt ein kompaktes lokales Sprachmodell (Llama 3.2 mit 3 Milliarden Parametern) auf dem VPS bereit. Es wird primär für den OpenClaw-Heartbeat verwendet — einen periodischen Check alle 30 Minuten, der prüft ob Aufgaben zu erledigen sind. Da dieser Check sehr einfach ist, braucht es dafür kein teures externes Modell.
Ollama ist ausschließlich intern erreichbar und hat keine öffentlichen Ports. Es lauscht auf einer internen IP des Docker-Netzwerks und ist nur für OpenClaw direkt zugänglich. Das Modell läuft vollständig auf der CPU des VPS — GPU-Beschleunigung ist nicht nötig für ein 3B-Modell bei dieser Aufgabe.
Layer 4 — Data Layer: Daten bleiben isoliert
Zwei vollständig getrennte MariaDB 11-Instanzen laufen auf dem VPS. Die erste gehört zum Web-Stack und speichert die Daten von testn.eu. Die zweite (ghost_db) gehört ausschließlich Ghost und ist für keinen anderen Container zugänglich. Diese Trennung ist bewusst und wichtig: ein Datenbankproblem in einem Stack soll sich nicht auf den anderen auswirken.
Beide Datenbankcontainer haben keine nach außen exponierten Ports. Verbindungen sind ausschließlich über das interne Docker-Netzwerk möglich, und nur die jeweils zugehörigen Applikationscontainer kennen die Datenbankzugangsdaten. Die Credentials werden als Umgebungsvariablen zur Laufzeit übergeben und sind weder im Image noch in einem Repository gespeichert.
Neben den relationalen Datenbanken gibt es ein weiteres wichtiges Datenspeichermuster: JSON-Dateien auf gemounteten Volumes. Wetterdaten, Aktienkurse, News-Feeds — all das wird als JSON auf dem Host-Dateisystem gespeichert und von mehreren Containern gelesen. Dieser Ansatz ist für Read-heavy-Daten ideal: kein Datenbankoverhead, sofort lesbar, einfach zu debuggen.
Reihenfolge beim Aufsetzen — warum die Reihenfolge entscheidend war
Der erste Schritt war immer das Docker-Netzwerk. Alle Container müssen im selben internen Netz sein, damit sie sich gegenseitig per Container-Name ansprechen können. Ohne dieses Fundament funktioniert nichts, was danach kommt.
Als zweites kamen die Datenbanken. MariaDB muss laufen und getestet sein, bevor PHP-FPM oder Ghost gestartet werden — beide prüfen beim Start ob die Datenbank erreichbar ist. Ein Datenbankfehler beim ersten Start kann zu einem defekten Zustand führen, der ohne Datenverlust schwer zu bereinigen ist.
Dann kam nginx — aber noch ohne SSL. Zuerst läuft alles auf HTTP, um sicherzugehen dass das Routing funktioniert. Let's Encrypt-Zertifikate können erst beantragt werden wenn die Domain bereits auf den Server zeigt und HTTP-Challenges beantwortet werden können. Erst wenn HTTP funktioniert, kommt HTTPS dazu.
Ghost wurde nach dem Web-Stack aufgesetzt, weil es eine eigene Datenbank und eine eigene Domain braucht — beides musste bereits existieren. n8n kam danach, weil es auf funktionierende externe APIs angewiesen ist und getestet werden musste ob Outbound-Verbindungen vom VPS aus funktionieren. Ollama wurde installiert sobald klar war, welche lokalen Inferenz-Aufgaben anfallen. OpenClaw kam zuletzt — als Koordinationsschicht über allem anderen.
Absicherung: was geht nach außen, was bleibt drin
Die wichtigste Sicherheitsmaßnahme ist die konsequente Beschränkung auf einen einzigen öffentlichen Eintrittspunkt: nginx auf Port 80 und 443. Alle anderen Container haben keine nach außen exponierten Ports. Das bedeutet: selbst wenn ein Angreifer die IP-Adresse kennt, gibt es außer nginx nichts direkt anzugreifen.
Firewall-Regeln auf Host-Ebene verstärken das: nur Port 80, 443 und SSH sind von außen erreichbar. Alles andere wird verworfen, bevor es überhaupt den nginx-Container erreicht. SSH ist mit Key-only-Authentifizierung konfiguriert — Passwort-Login ist deaktiviert.
Credentials werden konsequent als Umgebungsvariablen übergeben, niemals hardcoded. API-Keys, Datenbankpasswörter, Bot-Tokens — alles liegt in .env-Dateien auf dem Host und wird beim Container-Start injiziert. Diese Dateien sind nicht versioniert und nicht öffentlich zugänglich.
OpenClaw hat Docker-Socket-Zugriff — das ist die mächtigste Berechtigung im System, weil damit theoretisch neue Container gestartet oder bestehende verändert werden können. Dieses Risiko ist bekannt und akzeptiert, weil OpenClaw der vertrauenswürdige Operator ist. Die Kommunikation läuft verschlüsselt über Telegram, und Aktionen die den Betrieb unterbrechen könnten werden immer zuerst als Plan kommuniziert und bestätigt.
Was wird wofür verwendet — die Übersicht
nginx: Einziger öffentlicher Zugangspunkt, SSL-Terminierung, Routing zu allen internen Diensten, statische Dateien.
web_php (PHP-FPM): Darstellung von testn.eu, Rendering von Wetter, News und Seiteninhalten aus JSON-Dateien, Aktualisierung von Aktienkursen via PHP-Skript.
web_db (MariaDB): Persistente Datenspeicherung für den Web-Stack.
Ghost: Publishing-Plattform für blog.testn.eu, vollständig KI-gestützt betrieben via Admin API. ghost_db (MariaDB): Isolierte Datenbank ausschließlich für Ghost.
n8n: Zeitgesteuerte Automatisierungen — Wetter, Börsenkurse, BTC, Server-Status, Telegram-Benachrichtigungen.
OpenClaw: KI-Agent und Infrastruktur-Operator, Telegram-Interface, Cron-Job-Management, Content-Erstellung, Deployment-Aufgaben.
Ollama: Lokale LLM-Inferenz für Heartbeat-Tasks und günstige Routine-Aufgaben ohne externe API-Kosten.
Fazit: Modularität als Prinzip
Was diesen Stack von einem klassischen LAMP-Server unterscheidet, ist nicht die Technologie — es ist das Prinzip. Jeder Container hat genau eine Aufgabe. Jede Verbindung zwischen Containern ist explizit und begründet. Kein Dienst weiß mehr über seine Umgebung als nötig. Das Ergebnis ist eine Infrastruktur, die sich selbst verwaltet, täglich Daten sammelt, Inhalte publiziert, mich über Telegram informiert — und das alles ohne dass ich täglich eingreifen muss.
Dieser Stack wächst weiter. Neue Workflows kommen dazu, neue Automatisierungen, neue Blog-Inhalte — alles entstanden durch Gespräche mit einem KI-Agenten
